Succesvolle projecten in automatisering
Van bankafschriftanalyse tot complexe factuurherkenning: ontdek hoe EasyData organisaties transformeert met bewezen AI-oplossingen. 25+ jaar Nederlandse expertise in documentverwerking voor efficientere processen en verbeterde compliance.

Waarom kiezen organisaties voor EasyData?
Voor een IT-manager bij een gemeente leek het onmogelijk: duizenden bankafschriften van verschillende banken automatisch verwerken, zonder dat privacygevoelige informatie werd opgeslagen. Tot hij kennismaakte met de Financial Search-oplossing van EasyData.
Deze introductie illustreert perfect waar dit artikel over gaat: hoe EasyData organisaties helpt om complexe documentverwerkingsprocessen te automatiseren met Europese technologie en eigen datacenters. In dit artikel ontdek je concrete voorbeelden van succesvolle projecten, van factuurherkenning tot handschriftherkenning, en waarom deze oplossingen nu relevanter zijn dan ooit.
Met de toenemende digitalisering en strengere privacy-eisen zoeken organisaties naar betrouwbare partners die zowel innovatie als compliance kunnen garanderen. EasyData combineert meer dan 25 jaar ervaring met geavanceerde cloudoplossingen en biedt daarmee een unieke propositie in de markt.
Bankafschriftanalyse voor Nederlandse gemeente

Nederlandse gemeenten staan voor de uitdaging om bankafschriften van verschillende banken (ABN Amro, ING, Rabobank en SNS) snel en veilig te verwerken. De kern van de oplossing hebben we succesvol opgelost met onze Financial Search-technologie, die automatisch documenten herkent, relevante data extraheert en transacties categoriseert volgens een dynamisch systeem.
Het unieke van deze aanpak is dat categorieen geen persoonsgegevens bevatten en – indien gewenst – gedeeld kunnen worden met andere aangesloten gemeenten. Hierdoor ontstaat een netwerk van best practices die breed inzetbaar zijn.
Belangrijke voordelen voor de klant:
- Volledige privacy: Geen opslag van persoonsgegevens; verwerking vindt plaats in streng afgeschermde omgeving
- Flexibiliteit: Categorie-indelingen kunnen eenvoudig worden aangepast aan veranderende regelgeving
- Veiligheid: Bestanden worden via beveiligde kanalen aangeleverd en na verwerking direct verwijderd
- Schaalbaarheid: Geschikt voor grote volumes documenten met transparante staffelprijzen
- Uitbreidbaarheid: Naast bankafschriften kunnen ook andere documentsoorten worden toegevoegd
De implementatie omvatte tevens een servicedeskportal, logging van gebruikers en uitgebreide ondersteuning. Dankzij deze geintegreerde aanpak kunnen de aangesloten gemeenten haar financiele processen efficienter en veiliger inrichten, met behoud van volledige privacy en compliance.
Automatische factuurverwerking voor middelgroot bedrijf
Een succesvol project betrof de automatisering van het factuurverwerkingsproces voor een middelgroot Nederlands bedrijf. Het doel was handmatige verwerking van binnenkomende pdf-facturen te minimaliseren en de administratieve efficientie te verhogen.
Binnenkomende pdf-facturen worden automatisch herkend op regelniveau. Facturen die al een XML-bestand bevatten, worden direct doorgestuurd naar de gewenste serverlocatie. De herkende facturen worden via een beveiligde verbinding geplaatst in een map die direct toegankelijk is voor het ERP-systeem van de klant.
Bijzondere functionaliteiten:
Online verificatie: Facturen die niet volledig automatisch herkend worden, gaan naar een online verificatiemodule. Indien handmatige correctie nodig is, ontvangt de verantwoordelijke medewerker automatisch een melding per e-mail.
Continue verbetering: Klanten kunnen onvolledig herkende facturen eenvoudig aanleveren voor procesoptimalisatie, waardoor het systeem steeds slimmer wordt.
Concrete resultaten:
- Tijdswinst: Verwerking verloopt grotendeels automatisch, waardoor medewerkers zich kunnen richten op belangrijkere taken
- Betrouwbaarheid: Minder kans op fouten door automatische herkenning en controle
- Kostenbesparing: Scherp tarief per factuur en verminderde handmatige handelingen
- Maatwerk mogelijk: Verwerking van verzamel- of afwijkende facturen naar specifieke wensen
OCR-verbetering voor zorgsector
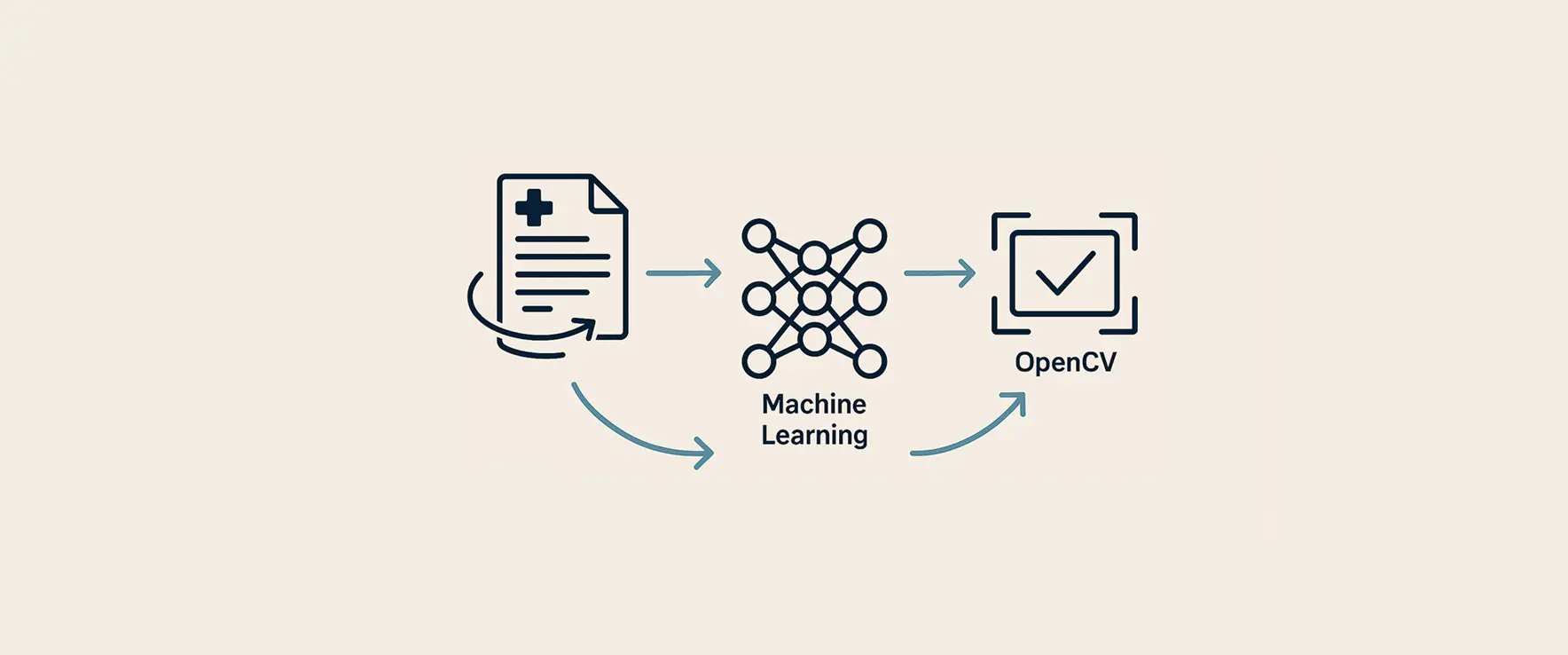
Voor een toonaangevende organisatie in de zorgsector hebben wij een innovatief project uitgevoerd gericht op het verbeteren van de herkenning van moeilijk leesbare documenten. Een aanzienlijk deel van aangeleverde documenten kon niet automatisch herkend worden door bestaande OCR-systemen.
We ontwikkelden een geavanceerde beeldverbetermodule gebaseerd op machine learning en OpenCV. Deze module corrigeert perspectief, herstelt vervormingen en verhoogt de resolutie van documenten, zodat ze optimaal voorbereid zijn voor automatische herkenning.
Technische innovaties:
Hybride OCR-workflow: Na beeldverbetering worden alleen relevante documentdelen via een beveiligde workflow herkend met behulp van Azure Advanced OCR. Dit waarborgt privacy en versnelt het proces.
Document splitting en samenvoeging: Onze technologie splitst documenten logisch in herkenbare delen, waarna resultaten worden samengevoegd tot een overzichtelijk tekstbestand met pdf-referentie.
Resultaten voor de klant:
- Hogere herkenningsgraad: Aanzienlijk meer documenten worden automatisch herkend
- Efficientere workflow: Doorlooptijd van documentverwerking is fors verkort
- Schaalbaarheid: Geschikt voor grote aantallen documenten en uitbreidbaar met nieuwe technologieen
- Kostenbesparing: Directe besparing op tijd en operationele kosten door minder handmatige verwerking
Complexe factuurherkenning voor internationale organisatie
Voor een internationaal opererende organisatie hebben wij een project uitgevoerd waarbij het automatiseren van complexe factuurverwerking centraal stond. De klant liep tegen uitdagingen aan zoals hoge afhankelijkheid van handmatige verwerking, foutgevoeligheid en beperkte flexibiliteit.

We implementeerden een geavanceerde oplossing die facturen automatisch herkent en relevante gegevens – zoals leveranciers, bedragen, btw-tarieven en valuta – direct uit documenten extraheert. Hierbij werd gebruikgemaakt van een combinatie van sjabloonherkenning en machine learning.
Bijzondere kenmerken:
Schaalbare integratie: Volledig geintegreerd met bestaand ERP-systeem voor naadloze workflow en preventie van dubbele invoer.
Flexibele aanpassingen: Specifieke wensen rondom btw-afhandeling en multicurrency-ondersteuning gerealiseerd door maatwerkregels. Organisaties kunnen eenvoudig inspelen op veranderende wet- en regelgeving.
Concrete verbeteringen:
- Kortere doorlooptijd van factuurverwerking*
- Drastische foutreductie ten opzichte van handmatige invoer
- Snelle uitbreiding nieuwe leveranciers en factuurformaten
- Internationale schaalbaarheid met ondersteuning voor meerdere valuta en btw-regimes
Geautomatiseerde postverwerking overheidsorganisatie

Voor een overheidsorganisatie hebben wij een project uitgevoerd dat volledig gericht was op het moderniseren van de verwerking van inkomende post en documenten. De uitdaging lag in het efficient verwerken van zowel papieren als digitale poststromen, het waarborgen van privacy en het realiseren van koppelingen met bestaande zaaksystemen.
We implementeerden een oplossing waarmee zowel fysieke als digitale documenten centraal worden gescand, herkend en automatisch voorzien van relevante metadata. Er wordt onderscheid gemaakt tussen technische en inhoudelijke metadata, afgestemd op de organisatiewensen.
Innovatieve functionaliteiten:
Koppeling met zaaksystemen: Gescande documenten worden, na herkenning en classificatie, via beveiligde koppeling aangeboden aan het zaaksysteem. Dit maakt het mogelijk documenten direct als startpunt van nieuwe zaken te gebruiken.
AI en OCR-technologie: Door inzet van geavanceerde OCR en AI-modellen worden documenten nauwkeurig herkend en geclassificeerd. Ook handschriftherkenning (ICR) en QR-codeherkenning zijn geintegreerd.
Resultaten voor de organisatie:
- Efficiente postverwerking: Doorlooptijd sterk verkort en fouten geminimaliseerd
- Flexibiliteit: Modulair opgebouwd en eenvoudig uitbreidbaar met nieuwe documentsoorten
- Kostenbesparing: Vermindering handmatige werkzaamheden en optimaal benutten bestaande infrastructuur
- Privacy en controle: Volledige regie over data en processen met maximale privacywaarborging
Identiteitsdocument herkenning telecombranche
Voor een grote speler in de telecom- en technologiebranche hebben wij een project uitgevoerd dat zich richtte op het optimaliseren van het scan- en herkenproces van uiteenlopende documenten, zoals identiteitsbewijzen, bankpassen, kassabonnen en KvK-uittreksels.
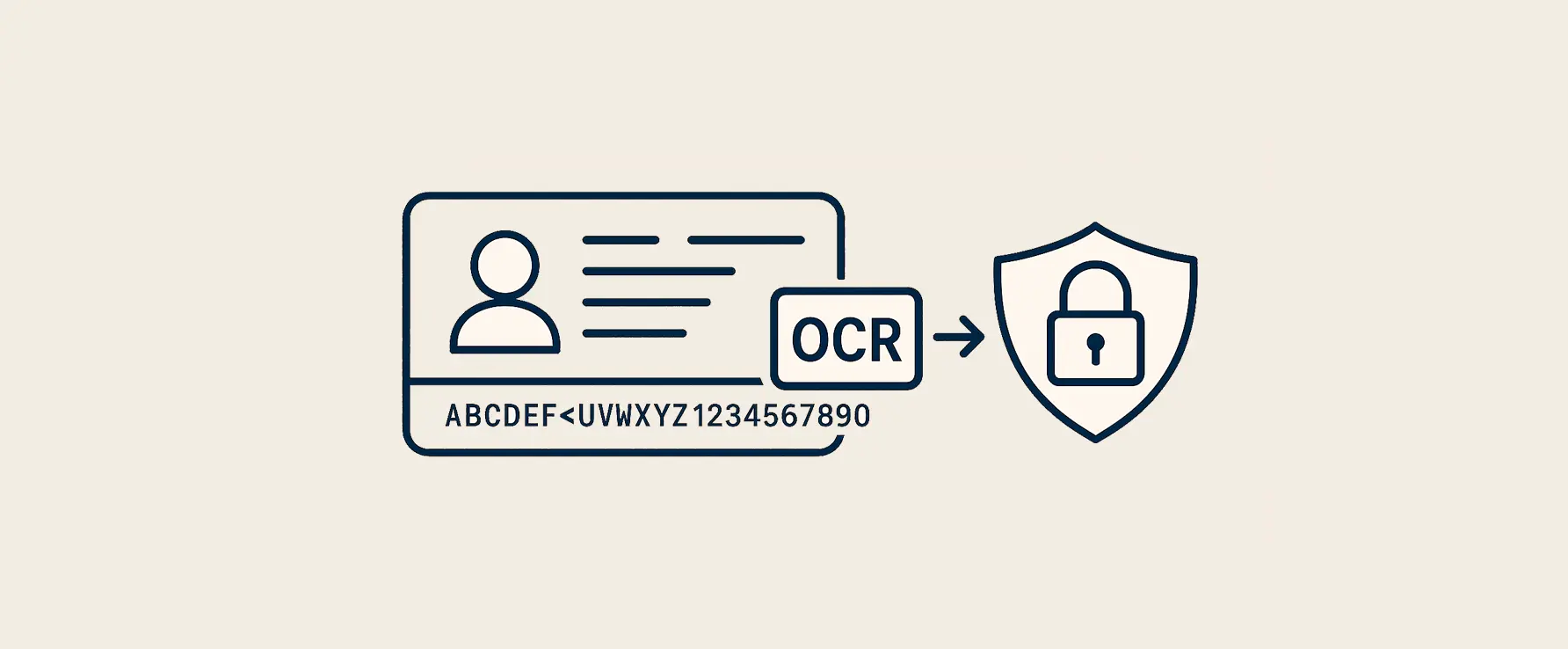
Met behulp van onze EasyData OCR Technology worden documenten zoals paspoorten, ID-kaarten, rijbewijzen en bankpassen automatisch herkend en relevante gegevens uitgelezen. Voor Europese identiteitsdocumenten wordt de MRZ (Machine Readable Zone) als basis gebruikt voor betrouwbare en snelle data-extractie.
Privacy by design:
Om te voldoen aan AVG-regelgeving wordt gewerkt met geanonimiseerde trainingsdata. Indien niet volledig geanonimiseerd gewerkt kan worden, worden datasets samengesteld waarbij steeds een van de hoofdvelden geanonimiseerd is, zodat privacy van eindgebruikers gewaarborgd blijft.
Concrete voordelen:
- Hogere betrouwbaarheid: Minder fouten bij toevoegen en verwerken van documenten
- Efficientie en tijdwinst: Handmatige controles grotendeels overbodig
- Privacy en compliance: Volledige naleving privacywetgeving door geanonimiseerde data
- Soepele implementatie: Modulaire opzet en centrale aansturing voor snelle invoering
End-to-end automatisering financiele dienstverlening
Voor een internationale dienstverlener in de financiele sector hebben wij een project uitgevoerd gericht op het volledig automatiseren van de verwerking van uiteenlopende documenten, zoals contracten, facturen en klantformulieren. De organisatie had te maken met grote volumes documenten die dagelijks binnenkwamen via verschillende kanalen (e-mail, uploads, cloudmappen).
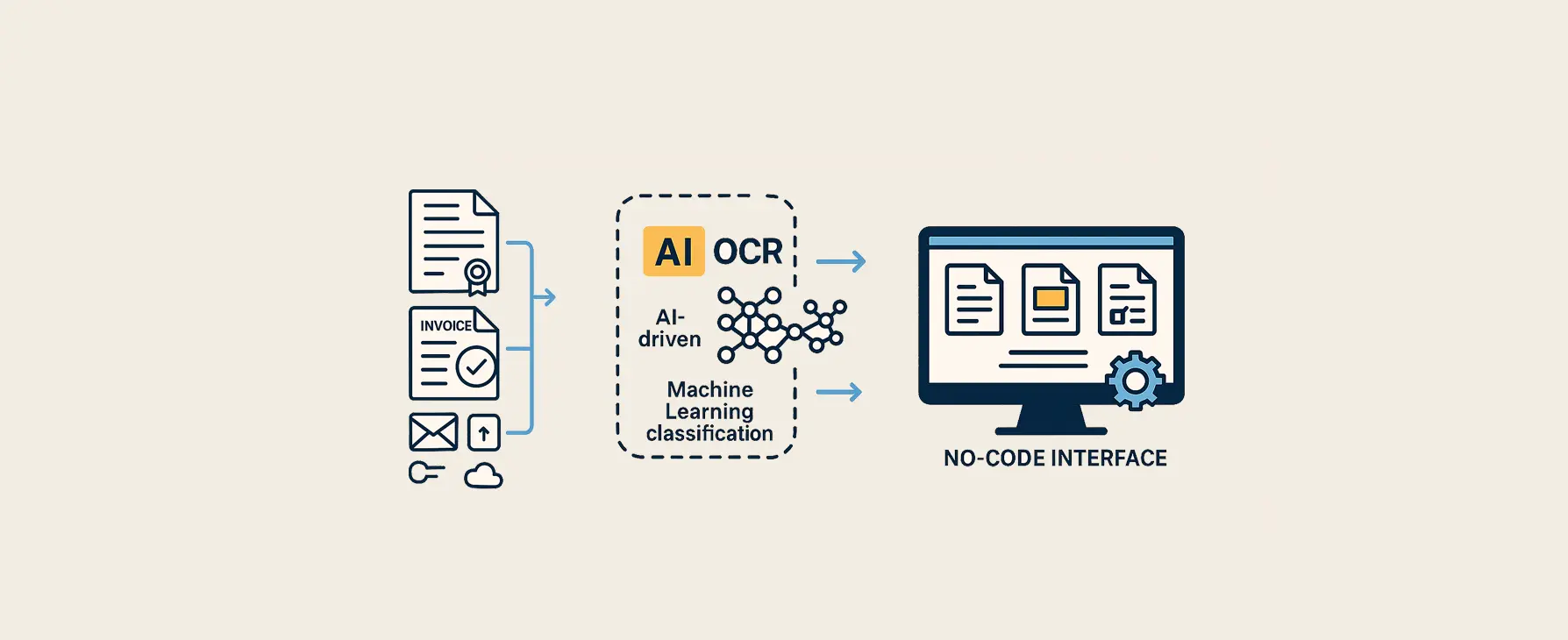
No-code flexibiliteit:
Gebruiksvriendelijke configuratie: De automatisering is ingericht voor verschillende documentsoorten, waaronder facturen, contracten, verzendlabels en klantformulieren. Dankzij een no-code interface kunnen medewerkers eenvoudig sjablonen aanmaken en aanpassen, zonder programmeerkennis.
We hebben een workflow opgezet waarbij documenten automatisch worden opgehaald uit verschillende bronnen, herkend, gecategoriseerd en relevant gegevens geextraheerd met behulp van AI-gedreven OCR en machine learning-technologie. De geextraheerde data wordt automatisch gevalideerd en direct doorgestuurd naar achterliggende systemen.
Meetbare verbeteringen:
- Tijdsbesparing: Verwerkingstijd gereduceerd van uren naar seconden
- Minder fouten: Foutenpercentage bij gegevensinvoer drastisch gedaald
- Schaalbaarheid: Moeiteloos verwerken van grote volumes, ook tijdens pieken
- Kostenbesparing: Lagere operationele kosten door minder handmatig werk
Automatische tekeningherkenning maakindustrie
Voor een toonaangevend bedrijf in de maakindustrie hebben wij een geavanceerd project gerealiseerd gericht op het automatiseren van technische documentverwerking en het uitvoeren van complexe berekeningen op basis van tekeningen. De uitdaging was om gegevens uit lastekeningen automatisch te extraheren, te valideren en direct te vertalen naar nauwkeurige berekeningen voor productie en kwaliteitscontrole.
Hotfolder-automatisering:
Automatische documentverwerking: Via een hotfolder worden digitale tekeningen automatisch ingelezen zodra ze in de juiste map worden geplaatst. Het systeem verwerkt direct pdf-bestanden met vectorafbeeldingen en tekstlagen, waardoor handmatige uploads of sortering overbodig zijn.
Met behulp van machine learning worden specifieke lassymbolen en relevante parameters (zoals materiaalsoort, plaatdikte, laslengte en hoek) automatisch herkend en uit de tekeningen gehaald. Ontbrekende of onduidelijke velden worden gemarkeerd, zodat de gebruiker deze eenvoudig kan aanvullen of corrigeren via een gebruiksvriendelijk webportaal.
Resultaten voor de klant:
- Efficientie: Verwerkingstijd van technische documenten drastisch verkort
- Nauwkeurigheid: Automatische herkenning en validatie minimaliseren menselijke fouten
- Gebruiksgemak: Eenvoudige controle en aanvulling van data via webportaal
- Volledige privacy: Lokale verwerking zonder internetverbinding voor optimale beveiliging
Materiaalcertificaten internationale industrie
Voor een internationale industriele organisatie hebben wij een project uitgevoerd gericht op het automatisch uitlezen en structureren van complexe certificaatdocumenten, zoals materiaalcertificaten voor staal en andere metalen. De uitdaging lag in het feit dat deze documenten semi-gestructureerd waren: tabellen en gegevens kwamen in verschillende vormen voor, met uiteenlopende indelingen.

Layout-specifieke extractie:
Maatwerk per documenttype: Op basis van de ontvangen documenten zijn zes unieke lay-outs geidentificeerd. Voor elke lay-out is een eigen extractiemodule ontwikkeld, afgestemd op de specifieke structuur en presentatie van de data. Dit garandeert een hoge nauwkeurigheid, ook bij afwijkende of minder gestructureerde tabellen.
Om de kwaliteit van de extractie te verhogen, zijn referentielijsten gebruikt voor materiaalsoorten, “Heat No.”-formaten en diameterbereiken. Hierdoor worden fouten bij het uitlezen en valideren van waarden tot een minimum beperkt en kunnen afwijkingen direct gesignaleerd worden.
Concrete resultaten:
- Efficientie: Handmatige invoer en controle grotendeels vervangen door automatische extractie
- Betrouwbaarheid: Validatie tegen referentielijsten zorgt voor verbeterde datakwaliteit
- Gebruiksgemak: Uploaden en verwerken via beveiligde NextCloud-omgeving
- Toekomstbestendigheid: Nieuwe documenttypes eenvoudig toe te voegen
Historische archiefdigitalisering

Voor een archiefinstelling die te maken had met grote hoeveelheden historische documenten – waaronder kaarten met handgeschreven aantekeningen, dossiers en inventarislijsten – hebben wij een project uitgevoerd gericht op het automatiseren van de herkenning en digitalisering van zowel handgeschreven als getypte teksten. De uitdaging lag in de enorme variatie aan handschriften, potloodnotities en wisselende scan- en papierkwaliteit.
Multi-engine benadering:
Gecombineerde technologieen: We hebben verschillende OCR- en HTR-systemen ingezet, waaronder EasyData OCR, Yandex Vision en Transcribus, om handgeschreven en gemengde teksten automatisch te herkennen. Door deze systemen slim te combineren, werd de kans op succesvolle extractie aanzienlijk vergroot.
Voor documenten met vage potloodnotities of lage scanresolutie zijn beeldverbetermodules toegepast. De herkende tekst werd direct gebruikt om documenten te indexeren en te voorzien van metadata, zodat ze doorzoekbaar werden in het archiefsysteem.
Impactvolle resultaten:
- Drastische tijdsbesparing: Verwerkingstijd per document verkort met factor 3 tot 5
- Betere toegankelijkheid: Archiefstukken volledig doorzoekbaar voor onderzoekers
- Hogere datakwaliteit: Validatie met woordenlijsten verbetert nauwkeurigheid
- Privacy en compliance: Verwerking in beveiligde omgeving volgens archiefnormen
Fraudedetectie overheidsorganisatie
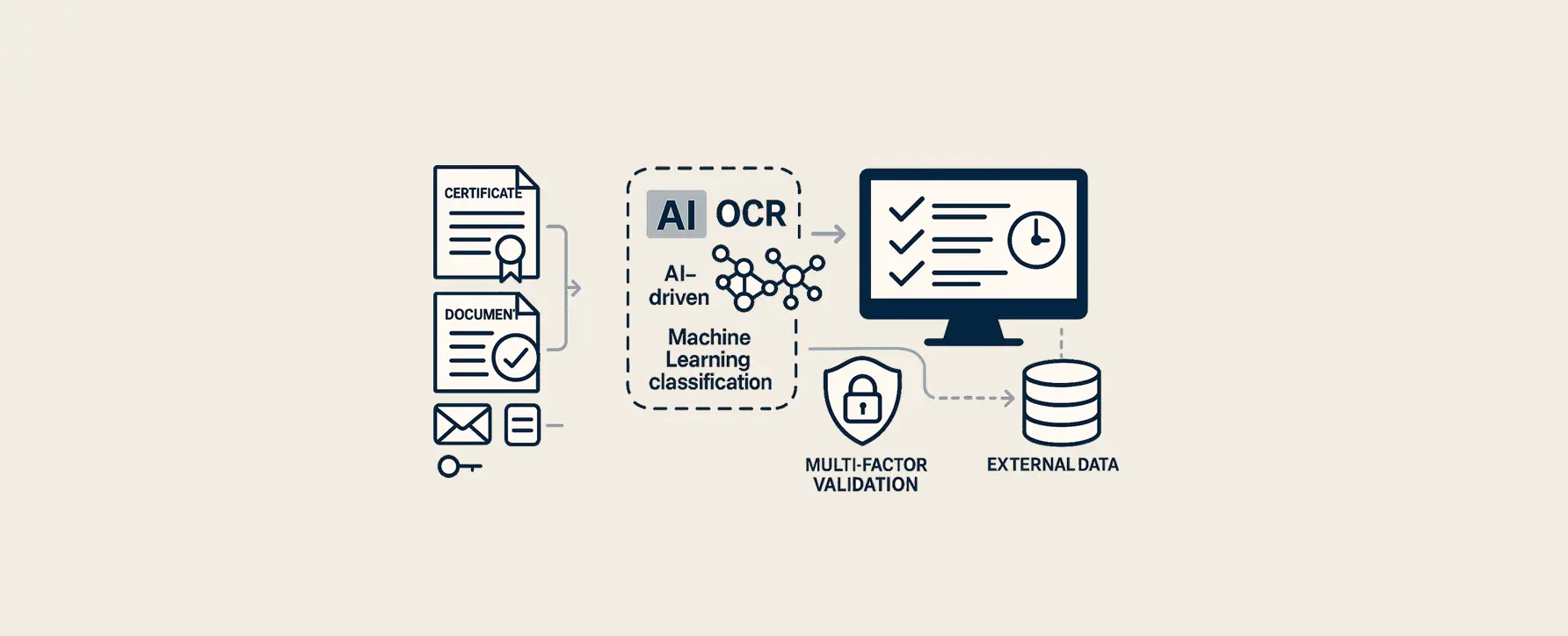
Voor een overheidsorganisatie hebben wij een innovatief project opgezet gericht op het automatiseren van de verwerking en validatie van certificaten en handelsdocumenten. De uitdaging was om snel en betrouwbaar onderscheid te maken tussen bonafide en frauduleuze documenten, waarbij zowel handschrift als machinegeschreven tekst herkend en geanalyseerd moest worden.
Externe data-integratie:
Multibronvalidatie: Waar nodig worden aanvullende gegevens automatisch opgehaald van betrouwbare online bronnen om de validatie te versterken en de volledigheid van de informatie te waarborgen. Dit verhoogt de betrouwbaarheid van fraudedetectie aanzienlijk.
Met behulp van onze eigen OCR-technologie en handschriftherkenningsmodules worden documenten nauwkeurig uitgelezen, waarbij ook ontbrekende of onduidelijke gegevens automatisch worden gesignaleerd. Documenten worden geclassificeerd en gevalideerd aan de hand van referentielijsten en metadata.
Veiligheids- en efficientie-voordelen:
- Snelle en betrouwbare herkenning: Doorlooptijd van inspecties aanzienlijk verkort
- Verbeterde fraudedetectie: Afwijkingen en mogelijke fraude sneller opgespoord
- Gebruiksvriendelijkheid: Overzichtelijke interface met mogelijkheid tot handmatige interventie
- Privacy en compliance: Volledige naleving privacywetgeving met minimale data-opslag
Geautomatiseerde orderverwerking handels- en distributiebedrijf

Voor een handels- en distributiebedrijf met een groot volume aan orderverwerking hebben wij een project uitgevoerd dat gericht was op het automatiseren en optimaliseren van het orderproces. De bestaande oplossing voldeed niet meer: belangrijke orderdetails gingen verloren en er was veel handmatige controle nodig, wat leidde tot vertragingen en fouten.
Machine learning-optimalisatie:
Zelflerend systeem: Orders die aan de validatiedrempel voldoen, worden direct geexporteerd als pdf met bijbehorende XML-data. Orders waarbij onzekerheid bestaat, komen in een online validatieportal (EasyVerify) terecht voor handmatige controle en training van het model. Hierdoor wordt het systeem steeds slimmer en neemt het aantal handmatige correcties af.
Het systeem is getraind op het herkennen van essentiele gegevens zoals afleveradres, klantnummer, e-mail, IBAN, telefoonnummers, ordernummers (zowel van de dealer als van de eindklant), en tabellen met aantallen en artikelnummers. Onbekende of onvolledige gegevens worden automatisch aangevuld via een database lookup.
Zakelijke voordelen:
- Efficientie: Verwerking van orders verloopt grotendeels automatisch met sterk verminderde doorlooptijd
- Kostenbesparing: Minder handmatige handelingen en scherp tarief per verwerkte order
- Gebruiksgemak: Eenvoudige controle, training en rapportage voor medewerkers
- Toekomstbestendig: Flexibel, schaalbaar en uitbreidbaar met nieuwe functionaliteiten
Documentanonimisering technologiebedrijf
Voor een technologiebedrijf gespecialiseerd in gegevensbescherming hebben wij een project uitgevoerd rondom de ontwikkeling en implementatie van een geavanceerde oplossing voor documentanonimisering. De klant wilde inspelen op de groeiende vraag naar privacybescherming bij het verwerken van grote hoeveelheden gevoelige documenten.

Named Entity Recognition:
Intelligente herkenning: Door het inzetten van geavanceerde machine learning-technologieen en NER-modellen werden persoonsgegevens, handtekeningen en gevoelige entiteiten automatisch herkend en geanonimiseerd. Het systeem leert continu bij op basis van feedback en nieuwe datasets.
We hebben het bestaande anonimiseringsplatform volledig geintegreerd met een schaalbare cloudomgeving. Hierdoor kunnen grote aantallen documenten snel en veilig verwerkt worden, waarbij de verwerking per pagina parallel verloopt voor maximale snelheid en capaciteit.
Strategische resultaten:
- Snelle verwerking: Grote hoeveelheden documenten in korte tijd veilig geanonimiseerd
- Hoge nauwkeurigheid: Betrouwbare herkenning en afscherming van gevoelige gegevens
- Flexibiliteit: Groeit mee met veranderende eisen en eenvoudig uit te breiden
- Marktpositie: Solide basis voor verdere groei en innovatie door samenwerking
Financiele rapportage conversie voor een landelijke organisatie

Voor een landelijke organisatie die verantwoordelijk is voor het inzichtelijk maken van grote hoeveelheden jaarrekeningen en financiele rapportages, hebben wij een project uitgevoerd waarin de conversie en structurering van ongestructureerde financiele documenten centraal stond. De uitdaging was om uit duizenden jaarverslagen snel en accuraat relevante financiele gegevens te extraheren.
Automatische webcrawling:
Intelligente verzameling: Met onze Financial Search-oplossing worden jaarrekeningen automatisch verzameld, herkend en omgezet naar gestructureerde data. Het systeem is in staat om op internet naar jaarverslagen te zoeken, deze te downloaden en te rubriceren op basis van relevante kenmerken zoals bedrijfsnaam, verslagjaar en beursnotering.
Door inzet van slimme algoritmen worden geconsolideerde balansen en andere kerngegevens automatisch herkend, gecontroleerd op compleetheid en samengebracht in een overzichtelijk Excelbestand of database. De export kan volledig worden afgestemd op de wensen van de klant en is geschikt voor verdere analyse of monitoring.
Analytische voordelen:
- Efficientie: Verwerkingstijd van jaarrekeningen drastisch verkort
- Betrouwbaarheid: Nauwkeurigheid van data sterk toegenomen door automatische validatie
- Inzicht en sturing: Diepgaande analyses mogelijk voor betere besluitvorming
- Toekomstbestendig: Groeit mee met nieuwe eisen en ontwikkelingen
Technische tekeningen archief optimalisatie attractiepark
Voor een groot Nederlands attractiepark hebben wij een project uitgevoerd gericht op het optimaliseren van de vindbaarheid en toegankelijkheid van een omvangrijk technisch archief. De uitdaging was om duizenden technische tekeningen, onderhoudsdocumenten en inventarislijsten beter doorzoekbaar te maken voor technische medewerkers.
Slimme metadata-verrijking:
Automatische structurering: Door slimme algoritmen toe te passen, konden we uit gescande documenten relevante gegevens extraheren en deze verrijken met metadata. Hierdoor werd het mogelijk om documenten te rubriceren op basis van bijvoorbeeld attractienaam, documenttype, jaartal of leverancier.
We zijn gestart met een grondige inventarisatie van het archiefmateriaal van meerdere attracties. Daarbij is gekeken naar de structuur van de bestaande mappen, de aanwezigheid van inventarislijsten en de kwaliteit van technische tekeningen en onderhoudsdocumenten. Voor documenten met matige scankwaliteit is beeldverbetering toegepast.
Operationele verbeteringen:
- Snelle vindbaarheid: Medewerkers kunnen eenvoudig zoeken en direct juiste documenten vinden
- Betere structuur: Archief is toekomstbestendig en flexibel door metadata-toevoeging
- Minder fouten: Centraal ontsluiten voorkomt dubbele of onvolledige scans
- Uitbreidbaarheid: Voorbereid op verdere digitalisering en nieuwe documenttypes
Transportdocumentverwerking logistiek dienstverlener

Voor een logistiek dienstverlener actief in de internationale handel hebben wij een project gerealiseerd gericht op het automatiseren van de verwerking en controle van transport- en vrachtgerelateerde documenten, zoals CMR’s, laad- en losformulieren, en begeleidende certificaten. De klant wilde handmatige controles drastisch verminderen en compliance-risico’s minimaliseren.
Compliance-automatisering:
Automatische validatie: Het systeem controleert automatisch of alle verplichte documenten aanwezig zijn. Ontbrekende of afwijkende documenten worden direct gesignaleerd, zodat medewerkers snel kunnen ingrijpen.
Alle aangeleverde transportdocumenten werden automatisch herkend en relevante gegevens uitgelezen. Het systeem is flexibel genoeg om verschillende talen, lay-outs en documenttypes te verwerken, inclusief handgeschreven en gestempelde velden.
Logistieke optimalisaties:
- Efficientie: Verwerkingstijd per transportdossier substantieel verkort*
- Foutreductie: Fouten en compliance-risico’s sterk verminderd door automatische validatie
- Transparantie: Documenten centraal geordend met volledige logging en audittrail
- Flexibiliteit: Eenvoudig aanpasbaar aan nieuwe documenttypes en compliance-eisen
Claimverwerking internationale verzekeraar
Voor een internationale verzekeraar hebben wij een project gerealiseerd dat het volledige proces van het verwerken van medische claims heeft getransformeerd.
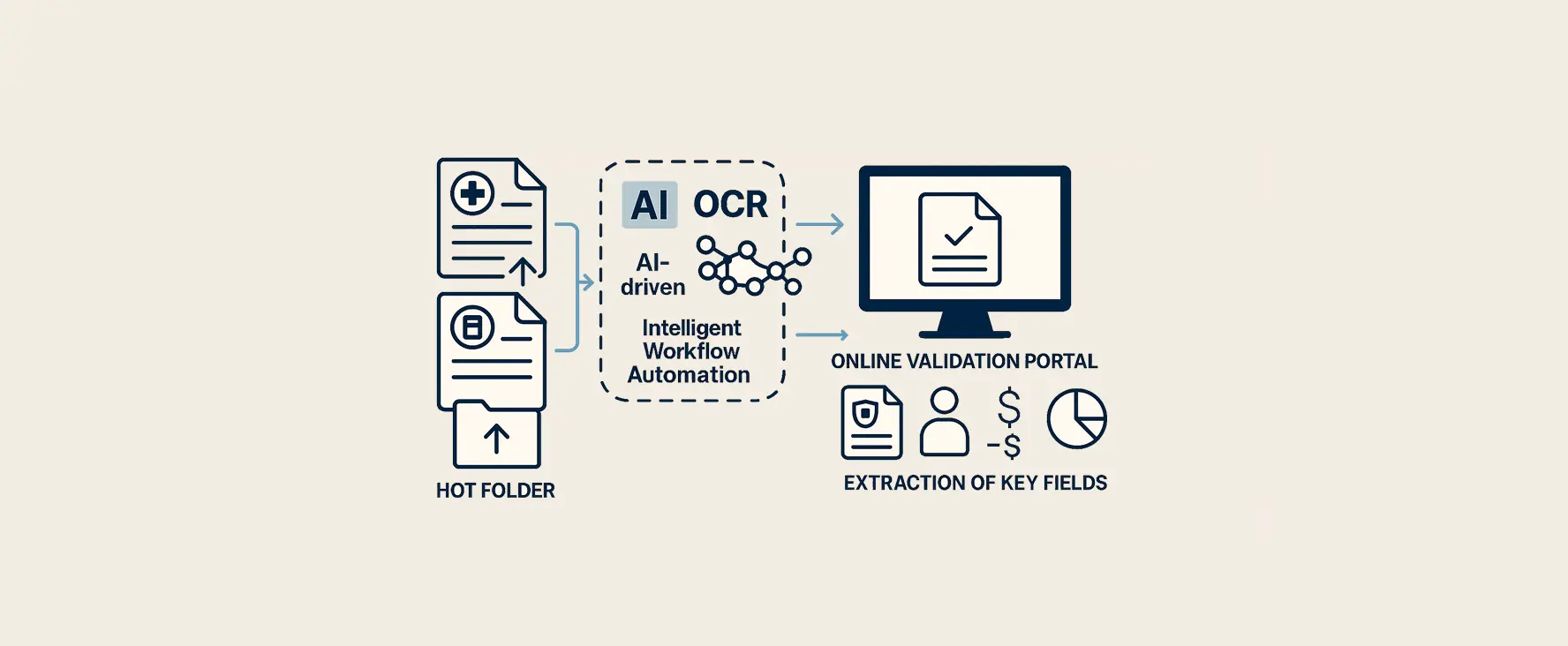
Intelligente workflowautomatisering:
Hotfolderverwerking: Documenten worden via een hotfolder automatisch opgepakt en verwerkt. Alleen documenten met onduidelijkheden worden doorgestuurd naar een online validatieportal. Hierdoor wordt de handmatige werkdruk drastisch verminderd.
Met behulp van een geavanceerd platform worden gescande claimdocumenten automatisch herkend. Belangrijke velden zoals polisgegevens, verzekerde aantallen, bedragen aan uitbetaalde en openstaande claims werden direct uit de documenten gehaald.
Verzekeringsgerelateerde voordelen:
- Efficientie: Verwerkingstijd van claims substantieel verkort*
- Nauwkeurigheid: Aantal fouten sterk verminderd door automatische validatie
- Kostenbesparing: Aanzienlijke daling van operationele kosten
- Toekomstbestendigheid: Groeit mee met nieuwe eisen en internationale uitbreidingen
WOZ-bezwaarverwerking regionale overheid
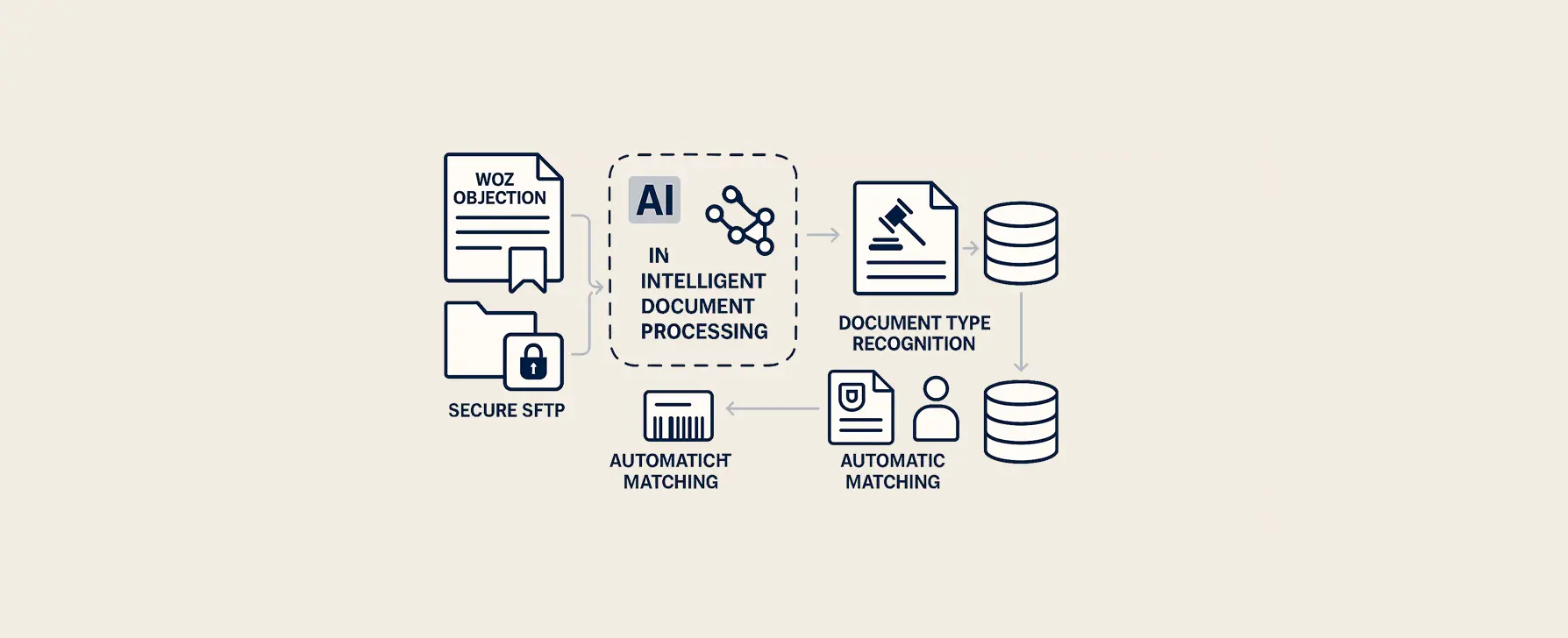
Voor een regionale overheidsorganisatie hebben wij een project uitgevoerd waarin het verwerken van bezwaar- en rechtbankdocumenten volledig is geautomatiseerd.
Intelligente dossierkoppeling:
Automatische matching: Door intelligente veldherkenning worden relevante gegevens zoals dossiernummer en klantnummer uitgelezen. Barcodes worden actief ingezet om herkenning te versnellen.
Binnenkomende bezwaarschriften worden automatisch vanaf een beveiligde SFTP-locatie opgehaald. Het systeem herkent het documenttype, leest aanslag- en dossiernummers uit en koppelt deze direct aan de juiste records in de database.
Overheidsspecifieke voordelen:
- Efficientie: Handmatige verwerking vrijwel overbodig met sterk verkorte doorlooptijd
- Betrouwbaarheid: Minimale kans op fouten door automatische matching
- Schaalbaarheid: Eenvoudig uitbreidbaar met nieuwe documenttypes
- Kostenbeheersing: Operationele kosten dalen en teamcapaciteit optimaal benut
Revolutie in automotive documentverwerking: van rigide sjablonen naar intelligente AI

Voor een toonaangevende softwareontwikkelaar die een krachtig documentmanagementsysteem ontwikkelt en vermarkt voor autodealers, hebben wij een baanbrekend project uitgevoerd. Het doel was het vervangen van hun bestaande rigide documentverwerkingsoplossing.
De uitdaging: 60+ documenttypen, oude technologie
Kritieke beperkingen van het oude systeem: Het bestaande systeem was volledig afhankelijk van een sjabloongebaseerde benadering. Ondersteuning van nieuwe documenttypen duurde tot wel 4 dagen, wat de schaalbaarheid ernstig belemmerde.
Meetbare resultaten na 2 maanden implementatie:
- Revolutionaire snelheidswinst: Ondersteuning nieuwe documenttypen gereduceerd van 4+ dagen naar minimale configuratietijd
- Verbeterde classificatieaccuratesse: AI-gedreven aanpak met confidence scoring
- Verhoogde data-extractieprecisie: Locatie-onafhankelijke veldextractie
- AVG-zekerheid: Automatische compliance voor gevoelige documenten
Enterprise ABBYY FlexiCapture Azure-infrastructuur

Voor een klant waar de bestaande ABBYY FlexiCapture implementatie eisen een maatje te groot bleken hebben wij een uitgebreid infrastructuurproject uitgevoerd voor de professionele setup en ondersteuning van hun ABBYY FlexiCapture cloud-infrastructuur op Microsoft Azure.
Complexe enterprise-infrastructuur: van analyse tot optimalisatie
Cost optimization door externe infrastructuur: Om kosten te optimaliseren implementeerden we een externe infrastructuur voor backup, resulterend in significante maandelijkse besparingen op Azure storage kosten.
Enterprise-level resultaten na 4 tot 6 weken implementatie:
- Complete infrastructuur setup: In 184 uur een professionele configuratie
- Automatische scaling: Load-responsive infrastructure die automatisch meegroeit
- Robuuste backupstrategieen: Dubbele backup met cost-optimized externe infrastructuur
- Databaseperformance: Geoptimaliseerde FlexiCapture database
- 6 maanden warranty: Kwaliteitsgarantie op alle werkzaamheden
Intelligente kredietverwerking

Voor een bank die we niet met name kunnen noemen hebben wij een baanbrekend project uitgevoerd dat het volledige kredietgoedkeuringsproces heeft getransformeerd. De bank kampte met extreem lange doorlooptijden bij het verwerken van kredietaanvragen.
Complexe documentuitdaging: geen standaardformaten
Unieke technische uitdaging: De grootste uitdaging lag in het ontbreken van gestandaardiseerde formaten voor salariscertificaten en contracten. EasyData ontwikkelde een hybride benadering die algoritmes combineert met machine learning.
Meetbare impact voor de bank:
- Dramatische tijdreductie: Goedkeuringstijden veelvoudig verkort
- Verbeterde klantervaring: Significant snellere responstijd
- Foutreductie: Neural network-modellen verminderen fouten
- Schaalbaarheid: Oplossing groeit mee met nieuwe productlijnen
Waarom deze projecten succesvol waren
Deze casussen tonen aan dat succesvolle documentautomatisering niet alleen draait om de nieuwste technologie, maar vooral om het begrijpen van specifieke klantbehoeften en het leveren van oplossingen die echt werken in de praktijk.
Gemeenschappelijke succesfactoren:
Europese technologie en compliance: Alle projecten werden uitgevoerd met EasyData’s eigen technologie, gehost in Nederlandse datacenters volgens Europese privacystandaarden.
Maatwerk binnen standaard frameworks: Elke oplossing werd aangepast aan specifieke wensen, maar gebouwd op bewezen technische fundamenten.
Hands-on implementatie: Door intensieve samenwerking en kennisoverdracht werden klanten zelfredzaam gemaakt in het gebruik van hun systemen.
Van bankafschriftanalyse tot handschriftherkenning, van factuurverwerking tot fraudedetectie – elk project toont aan hoe doordachte automatisering organisaties helpt om efficienter, nauwkeuriger en veiliger te werken. Het geheim ligt in het combineren van geavanceerde AI-technologie met diepgaand begrip van bedrijfsprocessen en een pragmatische implementatieaanpak.
Ben je benieuwd hoe EasyData ook jouw documentprocessen kan transformeren? Deze projecten vormen het bewijs dat effectieve automatisering binnen handbereik ligt, ongeacht de complexiteit van je documentstromen.
Klaar om van handmatige chaos naar slimme automatisering te gaan?
Sluit je aan bij de organisaties die al hun documentverwerking hebben geautomatiseerd. Ervaar zelf hoe verbeterde nauwkeurigheid en substantiele tijdsbesparing jouw organisatie transformeert, mogelijk binnen 8 weken operationeel.*
Nederlandse automatiseringsexpertise gegarandeerd
25+ jaar ervaring – Pioniers in documentautomatisering sinds 1999
Nederlandse datasoevereiniteit – Alle servers in eigen datacenters, volledige AVG-compliance
Geen afhankelijkheid – Open standaarden en volledige data-eigendom
8 weken implementatie – Van eerste contact tot werkende oplossing
Transparante prijsstelling – Geen verborgen kosten of onduidelijke licenties
Europese compliance – AVG-ready met Nederlandse datacenterlocatie
*Implementatietijdframe gebaseerd op gemiddelde projectduur bij Nederlandse klanten, individuele projecten kunnen varieren afhankelijk van organisatiegrootte en complexiteit.
Veelgestelde vragen over documentautomatisering
Hoe lang duurt de implementatie van een documentautomatiseringsoplossing?
De implementatietijd varieert afhankelijk van de complexiteit en scope. Eenvoudige factuurherkenning kan typisch binnen 2 tot 4 weken operationeel zijn, terwijl complexere oplossingen zoals volledige postverwerking 2 tot 3 maanden kunnen duren.* EasyData kenmerkt zich door korte implementatieperiodes door gebruik van bewezen technische frameworks.
Welke privacywaarborgen biedt EasyData?
Alle EasyData-oplossingen worden gehost in Nederlandse datacenters volgens Europese privacystandaarden. We werken met privacy-by-design principes, geanonimiseerde trainingsdata waar mogelijk, en bieden zowel cloud- als on-premise implementaties. Klanten behouden volledige controle over hun data.
Kunnen bestaande systemen gekoppeld worden?
Ja, EasyData specialiseert zich in naadloze integratie met bestaande ERP-, CRM- en zaaksystemen. Door gebruik van standaard API’s, XML-export en maatwerkkoppelingen zorgen we ervoor dat nieuwe automatisering aansluit op jouw huidige IT-infrastructuur zonder grote verstoringen.
Wat zijn de typische kostenbesparingen?
Nederlandse klanten rapporteren substantiele vermindering in verwerkingstijd, drastische vermindering van invoerfouten en significante lagere operationele kosten.* De exacte besparing hangt af van het huidige proces en het volume documenten, maar ROI wordt meestal binnen 12 tot 18 maanden behaald.
Hoe nauwkeurig is automatische documentherkenning?
De nauwkeurigheid varieert per documenttype en -kwaliteit. Voor gestructureerde documenten zoals facturen behalen we verbeterde nauwkeurigheid.* Voor complexere documenten zoals handgeschreven teksten ligt dit tussen acceptabele niveaus. Alle systemen hebben validatieworkflows voor menselijke controle waar nodig.
Is training van medewerkers nodig?
EasyData biedt uitgebreide training en documentatie bij elke implementatie. Door gebruik van gebruiksvriendelijke interfaces en no-code configuratie kunnen medewerkers snel zelfstandig werken. We verzorgen zowel lokale training als online workshops, afgestemd op jouw organisatie.
*Resultaten gebaseerd op interne metingen bij Nederlandse klanten, individuele resultaten kunnen varieren per organisatie en processcope.
Over de auteur
